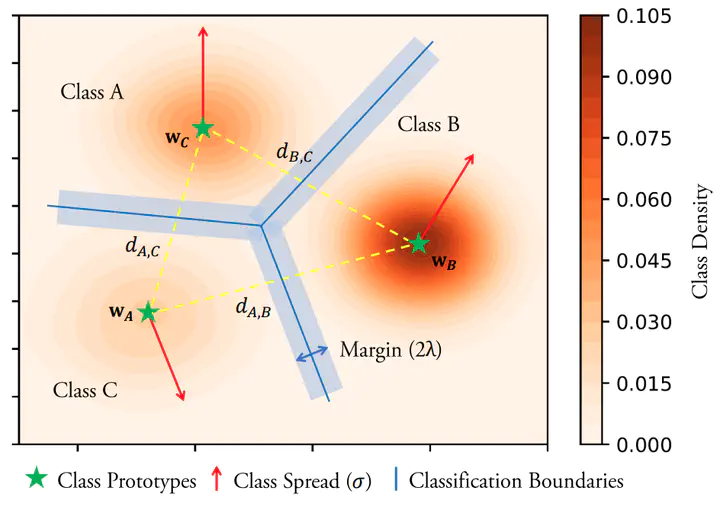
Abstract
Real-world object classes appear in imbalanced ratios. This poses a significant challenge for classifiers which get biased towards frequent classes. We hypothesize that improving the generalization capability of a classifier should improve learning on imbalanced datasets. Here, we introduce the first hybrid loss function that jointly performs classification and clustering in a single formulation. Our approach is based on an affinity measure in Euclidean space that leads to the following benefits. (1) direct enforcement of maximum margin constraints on classification boundaries, (2) a tractable way to ensure uniformly spaced and equidistant cluster centers, (3) flexibility to learn multiple class prototypes to support diversity and discriminability in feature space. Our extensive experiments demonstrate the significant performance improvements on visual classification and verification tasks on multiple imbalanced datasets. The proposed loss can easily be plugged in any deep architecture as a differentiable block and demonstrates robustness against different levels of data imbalance and corrupted labels.